1.讲一下Java的虚拟机
2.说说怎么能让虚拟机中的方法区直接爆满
3.讲一下Java的垃圾回收机制
4.把Java中的容器类都讲一下
5.Java中的锁是怎么实现的?
6.引用计数法有啥缺点呢
7.说一下TCP的三次握手和四次挥手
8.为什么挥手时有个time_wait?即2MSL
9.说一下浏览器输入URL都发生了什么,到页面出来的流程
10.操作系统中的死锁怎么形成的,怎么预防死锁
11.进程和线程有什么区别
12.线程的几种状态
13.线程池用过没,怎么使用,流程是啥
14.创建线程有哪些方法,有啥区别,你一般怎么创建
1. 讲一下Java的虚拟机

6. 引用计数法有啥缺点呢
1. 引用计数法(Java没有采用)
2. 标记-清除法 (jvm老年代回收)
3. 标记-压缩法 (jvm老年代回收)
4. 复制算法 (jvm新生代回收)
引用计数算法
给对象中添加一个引用计数器,每当有一个地方引用它时,计数器的值就加1;当引用失效时,计数器值就减1;任何时刻计数器为0的对象就是不可能再被使用的。这也就是需要回收的对象。
引用计数算法是对象记录自己被多少程序引用,引用计数为零的对象将被清除。
计数器表示的是有多少程序引用了这个对象(被引用数)。计数器是无符号整数。
计数器的增减
引用计数法没有明确启动 GC 的语句,它与程序的执行密切相关,在程序的处理过程中通过增减计数器的值来进行内存管理。
new_obj() 函数
与GC标记-清除算法相同,程序在生成新对象的时候会调用 new_obj()函数。

这里 pickup_chunk()函数的用法与GC标记-清除算法中的用法大致相同。不同的是这里返回 NULL 时,分配就失败了。这里 ref_cnt 域代表的是 obj 的计数器。
在引用计数算法中,除了连接到空闲链表的对象,其他对象都是活跃对象。所以如果 pickup_chunk()返回 NULL,堆中也就没有其它大小合适的块了。
update_ptr() 函数
update_ptr() 函数用于更新指针 ptr,使其指向对象 obj,同时进行计数器值的增减。
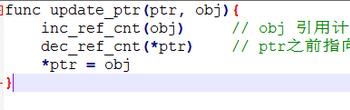
这里 update_ptr 为什么需要先调用 inc_ref_cnt,再调用dec_ref_cnt呢?
是因为有可能 *ptr和 obj 可能是同一个对象,如果先调用dec_ref_cnt可能会误伤。
inc_ref_cnt()函数
这里inc_ref_cnt函数只对对象 obj 引用计数 1
func inc_ref_cnt(obj){
obj.ref_cnt
}
dec_ref_cnt() 函数
这里 dec_ref_cnt 函数会把之前引用的对象进行-1 操作,如果这时对象的计数器变为0,说明这个对象是一个垃圾对象,需要销毁,那么被它引用的对象的计数器值都需要相应的-1。
func dec_ref_cnt(obj){
obj_ref_cnt–
if(obj.ref_cnt == 0)
for(child : children(obj))
dec_ref_cnt(*child) // 递归将被需要销毁对象引用的对象计数-1
reclaim(obj)
}
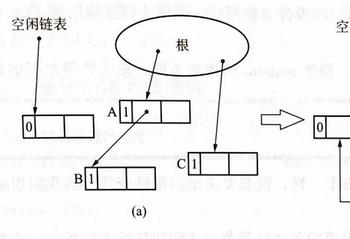
上图这里开始时,A 指向 B,第二步 A 指向了 C。可以看到通过更新,B 的计数器值变为了0,因此 B 被回收(连接到空闲链表),C 的计数器值由1变成了2。
通过上边的介绍,应该可以看出引用计数垃圾回收的特点。
在变更数组元素的时候会进行指针更新
通过更新执行计数可能会产生没有被任何程序引用的垃圾对象
引用计数算法会时刻监控更新指针是否会产生垃圾对象,一旦生成会立刻被回收。
所以如果调用 pickup_chunk函数返回 NULL,说明堆中所有对象都是活跃对象。
引用计数算法的优点
1.可立即回收垃圾
每个对象都知道自己的引用计数,当变为0时可以立即回收,将自己接到空闲链表
2.最大暂停时间短
因为只要程序更新指针时程序就会执行垃圾回收,也就是每次通过执行程序生成垃圾时,这些垃圾都会被回收,内存管理的开销分布于整个应用程序运行期间,无需挂起应用程序的运行来做,因此消减了最大暂停时间(但是增多了垃圾回收的次数)
最大暂停时间,因执行 GC 而暂停执行程序的最长时间。
3.不需要沿指针查找
产生的垃圾立即就连接到了空闲链表,所以不需要查找哪些对象是需要回收的
引用计数算法的缺点
1.计数器值的增减处理频繁
因为每次对象更新都需要对计数器进行增减,特别是被引用次数多的对象。
2.计数器需要占用很多位
计数器的值最大必须要能数完堆中所有对象的引用数。比如我们用的机器是32位,那么极端情况,可能需要让2的32次方个对象同时引用一个对象。这就必须要确保各对象的计数器有32位大小。也就是对于所有对象,必须保留32位的空间。
假如对象只有两个域,那么其计数器就占用了整体的1/3。
3.循环引用无法回收
这个比较好理解,循环引用会让计数器最小值为1,不会变为0。
循环引用

像这样,两个对象相互引用,所以各个对象的计数器都为1,且这些对象没有被其他对象引用。所以计数器最小值也为1,不可能为0。
延迟引用计数法
引用计数法虽然缩小了最大暂停时间,但是计数器的增减处理特别多。为了改善这个缺点,延迟引用计数法(Deferred Reference Counting)被研究了出来。
通过上边的描述,可以知道之所以计数器增减处理特别繁重,是因为有些增减是根引用的变化,因此我们可以让根引用的指针变化不反映在计数器上。比如我们把 update_ptr($ptr, obj)改写成*$ptr = obj,这样频繁重写对重对象中引用关系时,计数器也不需要修改。但是这有一个问题,那就是计数器并不能正确反映出对象被引用的次数,就有可能会出现,对象仍在活动,却被回收。
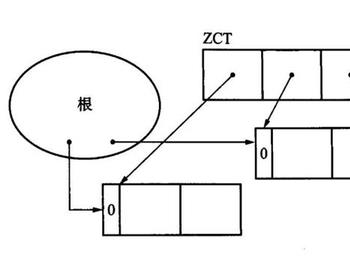
在延迟引用计数法中使用ZCT(Zero Count Table),来修正这一错误。
ZCT 是一个表,它会事先记录下计数器在 dec_ref_cnt()函数作用下变成 0 的对象。
ZCT
dec_ref_cnt 函数
在延迟引用计数法中,引用计数为0 的对象并不一定是垃圾,会先存入到 zct 中保留。
func dec_ref_cnt(obj){
obj_ref_cnt–
if(obj.ref_cnt == 0) //引用计数为0 先存入到 $zct 中保留
if(is_full($zct) == TRUE) // 如果 $zct 表已经满了 先扫描 zct 表,清除真正的垃圾
scan_zct()
push($zct, obj)
}
scan_zct 函数
func scan_zct(){
for(r: $roots)
(*r).ref_cnt
for(obj : $zct)
if(obj.ref_cnt == 0)
remove($zct, obj)
delete(obj)
for(r: $roots)
(*).ref_cnt–
}
第二行和第三行,程序先把所有根直接引用的计数器都进行增量。这样,来修正计数器的值。
接下来检查 $zct 表中的对象,如果此时计数器还为0,则说明没有任何引用,那么将对象先从 $zct中清除,然后调用 delete()回收。
delete() 函数定义如下:
func delete(obj){
for(child : children(obj)) // 递归清理对象的子对象
(*child).ref_cnt–
if (*child).ref_cnt == 0
delete(*child)
reclaim(obj)
}
new_obj() 函数
除 dec_ref_cnt 函数需要调整,new_obj 函数也要做相应的修改。
func new_obj(size){
obj = pickup_chunk(size, $free_list)
if(obj == NULL) // 空间不足
scan_zct() // 扫描 zct 以便获取空间
obj = pickup_chunk(size, $free_list) // 再次尝试分配
if(obj == NULL)
allocation_fail() // 提示失败
obj.ref_cnt = 1
return obj
}
如果第一次分配空间不足,需要扫描 $zct,以便再次分配,如果这时空间还不足,就提示失败
在延迟引用计数法中,程序延迟了根引用的计数,通过延迟,减轻了因根引用频繁变化而导致的计数器增减所带来的额外的负担。
但是,延迟引用计数却不能马上将垃圾进行回收,可立即回收垃圾这一优点也就不存在了。scan_zct函数也会增加程序的最大暂停时间。
Sticky 引用计数法
对于引用计数法,有一个不能忽略的部分是计数器位宽的设置。假设为了反映所有引用,计数器需要1个字(32位机器就是32位)的空间。但是这会大量的消耗内存空间。比如,2个字的对象就需要一个字的计数器。也就是计数器会使对象所占的空间增大1.5倍。
sticky 引用计数法就是用来减少位宽的。
如果我们为计数器的位数设为5,那么计数器最大的引用数为31,如果有超过31个对象引用,就会爆表。对于爆表,我们怎么处理呢?
1. 什么都不做
这种处理方式对于计数器爆表的对象,再有新的引用也不在增加,当然,当计数器为0 的时候,也不能直接回收(因为可能还有对象在引用)。这样其实是会产生残留的对象占用内存。
不过,研究表明,大部分对象其实只被引用了一次就被回收了,出现5位计数器溢出的情况少之又少。
爆表的对象大部分也都是重要的对象,不会轻易回收。
所以,什么都不做也是一个不错的办法。
2. 使用GC 标记-清除算法进行管理
这种方法是,对于爆表的对象,使用 GC 标记-清除算法来管理。
func mark_sweep_for_counter_overflow(){
reset_all_ref_cnt()
mark_phase()
sweep_phase()
}
首先,把所有对象的计数器都设为0,然后进行标记和清除阶段。
标记阶段代码为:
func mark_phase(){
for (r: $roots) // 先把根引用的对象推到标记栈中
push(*r, $mark_stack)
while(is_empty($mark_stack) == False) // 如果堆不为空
obj = pop($mark_stack)
obj.ref_cnt
if(obj.ref_cnt == 1) // 这里必须把各个对象及其子对象堆进行标记一次
for(child : children(obj))
push(*child, $mark_stack)
}
在标记阶段,先把根引用的对象推到标记栈中
然后按顺序从标记栈中取出对象,对计数器进行增量操作。
对于循环引用的对象来说,obj.ref_cnt > 1,为了避免无谓的 push 这里需要进行 if(obj.ref_cnt == 1) 的判断
清除阶段代码为:
func sweep_phase(){
sweeping = $heap_top
while(sweeping < $heap_end) // 因为循环引用的所有对象都会被 push 到 head_end 所以也能被回收
if(sweeping.ref_cnt == 0)
reclaim(sweeping)
sweeping = sweeping.size
}
在清除阶段,程序会搜索整个堆,回收计数器仍为0的对象。
这里的 GC 标记-清除算法和GC 标记-清除算法 主要不同点如下:
1.开始时将所有对象的计数器值设为0
2.不标记对象,而是对计数器进行增量操作
3.为了对计数器进行增量操作,算法对活动对象进行了不止一次的搜索。
这里将 GC 标记-清除算法和引用计数法结合起来,在计数器溢出后,对象称为垃圾也不会漏掉清除。并且也能回收循环引用的垃圾。
因为在查找对象时不是设置标志位而是把计数器进行增量,所以需要多次查找活动对象,所以这里的标记处理比以往的标记清除花的时间更长,吞吐量会相应的降低。
7. 为什么挥手时有个time_wait?即2MSL
TIME_WAIT主要是用来解决以下几个问题:
1)上面解释为什么主动关闭方需要进入TIME_WAIT状态中提到的: 主动关闭方需要进入TIME_WAIT以便能够重发丢掉的被动关闭方FIN包的ACK。如果主动关闭方不进入TIME_WAIT,那么在主动关闭方对被动关闭方FIN包的ACK丢失了的时候,被动关闭方由于没收到自己FIN的ACK,会进行重传FIN包,这个FIN包到主动关闭方后,由于这个连接已经不存在于主动关闭方了,这个时候主动关闭方无法识别这个FIN包,协议栈会认为对方疯了,都还没建立连接你给我来个FIN包?
于是回复一个RST包给被动关闭方,被动关闭方就会收到一个错误(我们见的比较多的:connect reset by peer,这里顺便说下 Broken pipe,在收到RST包的时候,还往这个连接写数据,就会收到 Broken pipe错误了),原本应该正常关闭的连接,给我来个错误,很难让人接受;
2)防止已经断开的连接1中在链路中残留的FIN包终止掉新的连接2(重用了连接1的所有的5元素(源IP,目的IP,TCP,源端口,目的端口)),这个概率比较低,因为涉及到一个匹配问题,迟到的FIN分段的序列号必须落在连接2的一方的期望序列号范围之内,虽然概率低,但是确实可能发生,因为初始序列号都是随机产生的,并且这个序列号是32位的,会回绕;
3)防止链路上已经关闭的连接的残余数据包(a lost duplicate packet or a wandering duplicate packet) 干扰正常的数据包,造成数据流的不正常。这个问题和2)类似。
MSL是Maximum Segment Lifetime英文的缩写,中文可以译为“报文最大生存时间”,他是任何报文在网络上存在的最长时间,超过这个时间报文将被丢弃。因为tcp报文(segment)是ip数据报(datagram)的数据部分,具体称谓请参见《数据在网络各层中的称呼》一文,
而ip头中有一个TTL域,TTL是time to live的缩写,中文可以译为“生存时间”,这个生存时间是由源主机设置初始值但不是存的具体时间,而是存储了一个ip数据报可以经过的最大路由数,每经过一个处理他的路由器此值就减1,当此值为0则数据报将被丢弃,同时发送ICMP报文通知源主机。RFC 793中规定MSL为2分钟,实际应用中常用的是30秒,1分钟和2分钟等。
2MSL即两倍的MSL,TCP的TIME_WAIT状态也称为2MSL等待状态,当TCP的一端发起主动关闭,在发出最后一个ACK包后,即第3次握手完成后发送了第四次握手的ACK包后就进入了TIME_WAIT状态,必须在此状态上停留两倍的MSL时间,等待2MSL时间主要目的是怕最后一个ACK包对方没收到,那么对方在超时后将重发第三次握手的FIN包,主动关闭端接到重发的FIN包后可以再发一个ACK应答包。
在TIME_WAIT状态时两端的端口不能使用,要等到2MSL时间结束才可继续使用。当连接处于2MSL等待阶段时任何迟到的报文段都将被丢弃。不过在实际应用中可以通过设置SO_REUSEADDR选项达到不必等待2MSL时间结束再使用此端口。
TTL与MSL是有关系的但不是简单的相等的关系,MSL要大于等于TTL。
9.说一下浏览器输入URL都发生了什么,到页面出来的流程
1、首先,在浏览器地址栏中输入url
2、浏览器先查看浏览器缓存-系统缓存-路由器缓存,如果缓存中有,会直接在屏幕中显示页面内容。若没有,则跳到第三步操作。
3、在发送http请求前,需要域名解析(DNS解析),解析获取相应的IP地址。
4、浏览器向服务器发起tcp连接,与浏览器建立tcp三次握手。
5、握手成功后,浏览器向服务器发送http请求,请求数据包。
6、服务器处理收到的请求,将数据返回至浏览器
7、浏览器收到HTTP响应
8、读取页面内容,浏览器渲染,解析html源码
9、生成Dom树、解析css样式、js交互
10、客户端和服务器交互
11、ajax查询
其中,步骤2的具体过程是:
浏览器缓存:浏览器会记录DNS一段时间,因此,只是第一个地方解析DNS请求;
操作系统缓存:如果在浏览器缓存中不包含这个记录,则会使系统调用操作系统,获取操作系统的记录(保存最近的DNS查询缓存);
路由器缓存:如果上述两个步骤均不能成功获取DNS记录,继续搜索路由器缓存;
ISP缓存:若上述均失败,继续向ISP搜索。
手撕代码:
思路:(可能不是很正规)
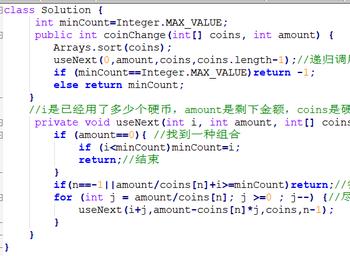
要使用尽可能少的硬币兑换,肯定是尽可能使用大额的硬币,但是有个问题是大额的硬币可能找不开啊,举个简单的例子:现在有100,30,1共三种硬币,我要凑120,尽可能使用大额硬币的话方案应该是一个100加上二十个1,很明显不对,没有四个30使用硬币少。 所以直接找还是不行,还是得递归或者回溯,我用的是直接递归,递归的过程就在代码里面体现了就不说了 ,说一下可取的点,虽然尽可能使用大额的硬币不能直接得到答案,但是我们可以得到一点有用的东西,我使用100的硬币得到的答案虽然不是最小的,但是也算是比较小的了,在这里是21枚硬币,我们可以借助这个21排除一些方案,比如我全选1的硬币肯定不行,120/1==120远大于21 直接排除。
代码: